
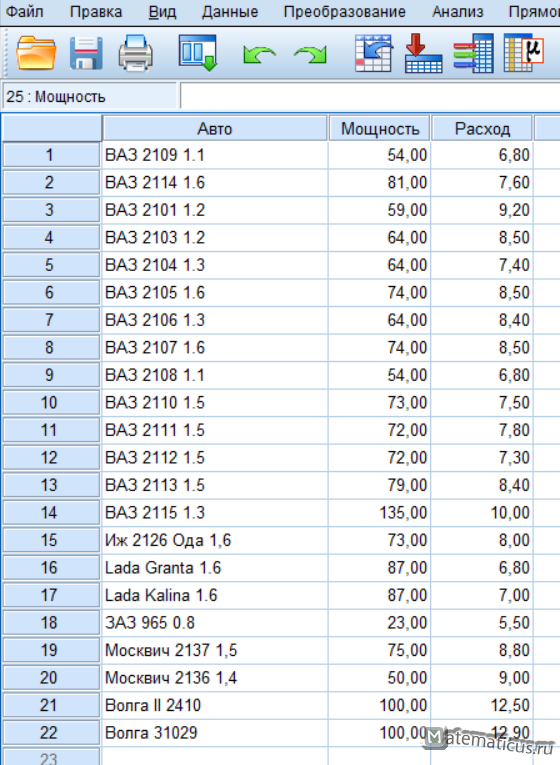
В целях реализации иерархической кластеризации в SPSS Statistics возьмем в качестве примера данные о некоторых приближенных характеристиках автомобилей – средний расход топлива и мощность двигателя в л.с.
Вводим три переменные, Авто — Мера номинальная, Мощность – Мера Шкалы, Расход – Мера Шкалы

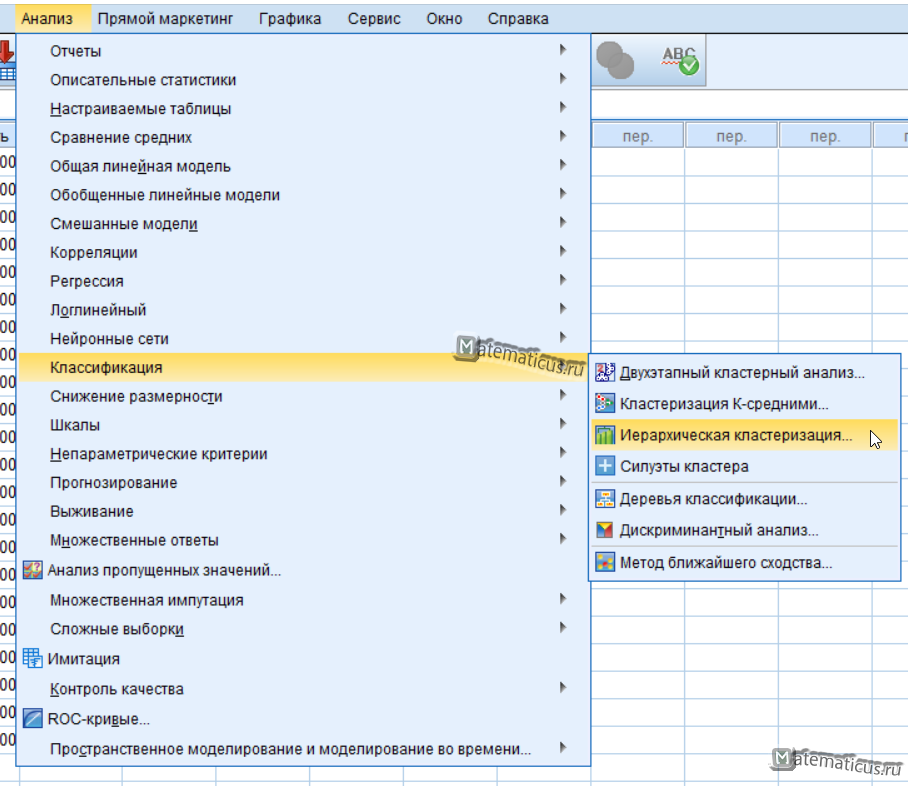
Переходим Анализ -> Классификация -> Иерархическая кластеризация
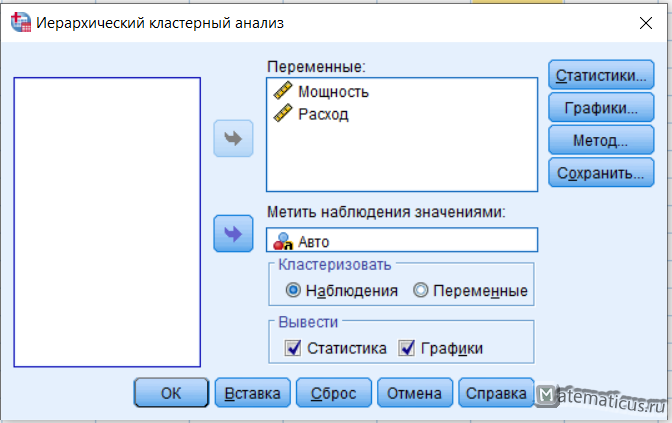
Появится окно — иерархический кластерный анализ.
В поле переменные вставляем Мощность и Расход. В поле метить наблюдения значениями вставляем Авто, ставим галочки вывести Статистика, Графики.
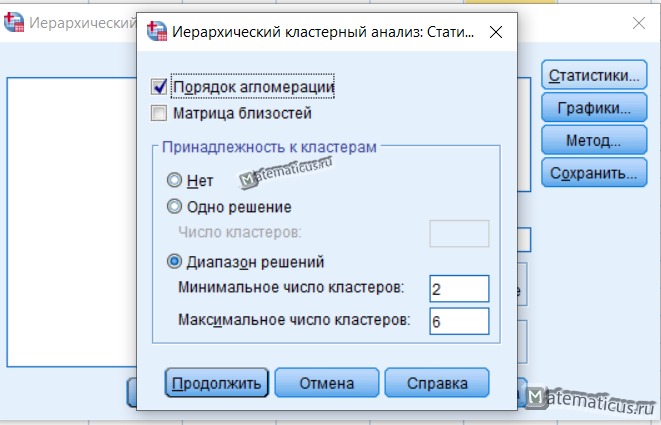
Нажимаем на кнопку Статистики, появляется соответствующее окно, ставим галку порядок агломерации в диапазоне решений указываем минимальное и максимальное число кластеров и жмем Продолжить.
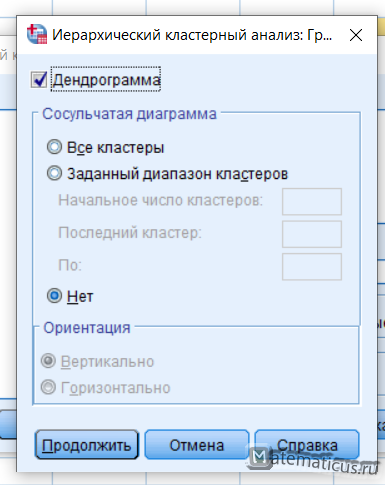
Нажимаем на кнопку Графики, появляется окно, ставим галку Дендрограмма и диаграмма — нет, далее жмем Продолжить.
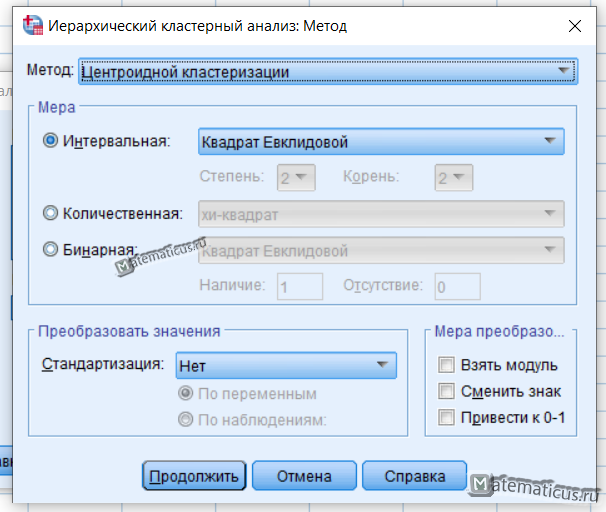
Нажимаем на кнопку Метод, появляется окно Метод, выбираем метод Центроидной кластеризации, мера – интервальная квадрат и жмем Продолжить.
Нажимаем Ок и SPSS Statistics выполняет расчет и получаем результаты иерархического кластерного анализа в SPSS
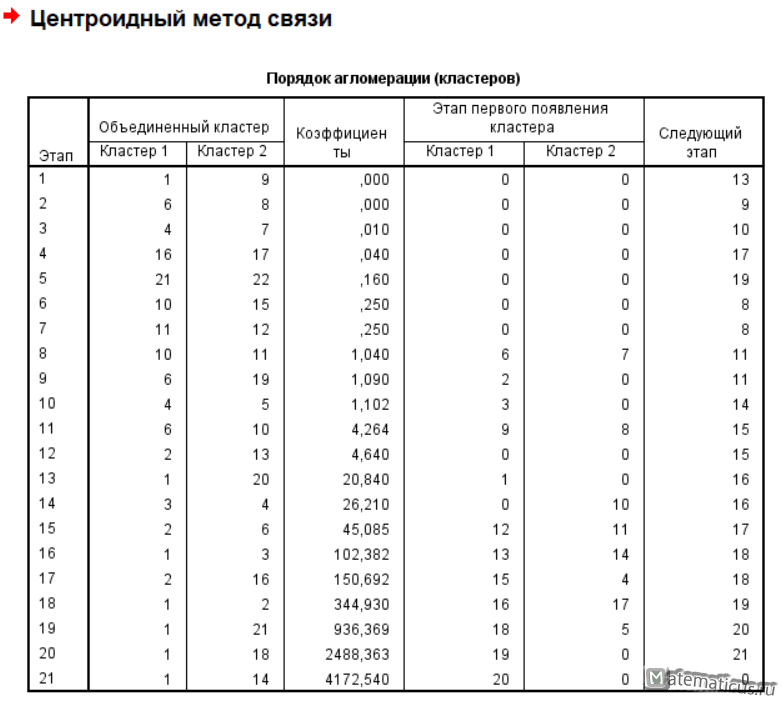
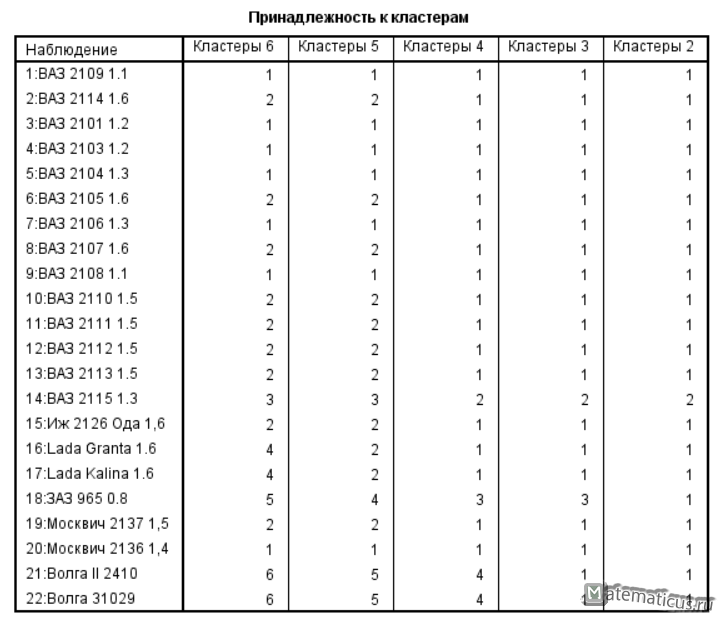
Принадлежность к кластерам
Дендрограмма с использованием метода центроида
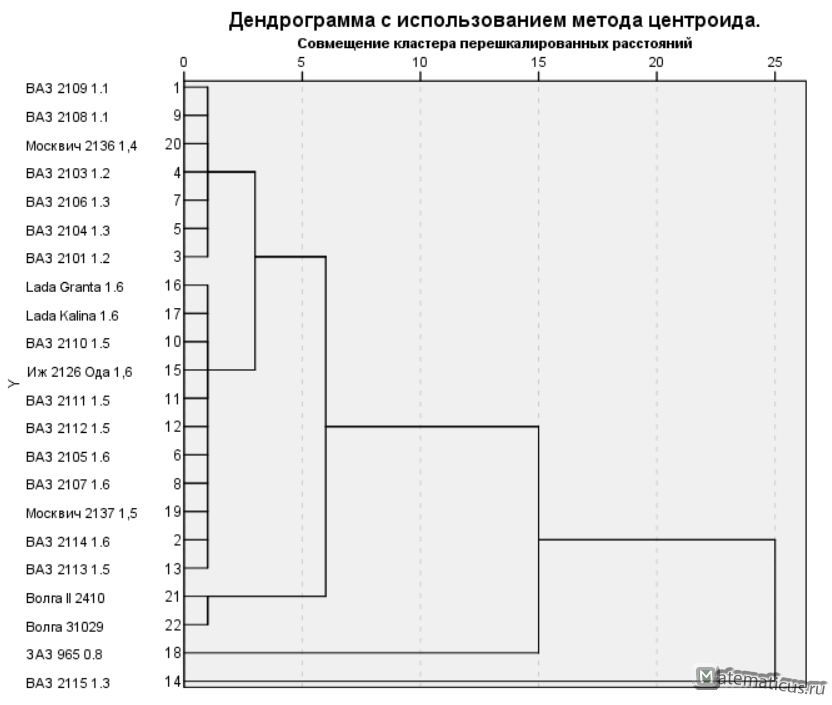
И что дальше? Как толковать эту дендрограмму?
Например, то, что такие автомобили, как Волга 2410 и Волга 31029 по таким характеристикам, как мощность двигателя и расход топлива близки друг другу и поэтому отнесены к отдельному кластеру и так далее. Таким образом в зависимость от выбранных характеристик и признаков — объекты можно классифицировать между собой.